
【不吐不快】关于Cloudflare于11.18故障的解读

一、情况呈现
2025 年 11 月 18 日 11:20 UTC,CF(Cloudflare,下文均简称CF) 的网络开始出现严重故障,无法正常传输核心网络流量。尝试访问的用户会看到一个错误页面,提示 CF 网络出现故障。
二、起因
一个权限更新 CF 有一个叫做“机器人管理”(Bot Management, BM)的模块,专门用来检测访问网站的是真人还是爬虫程序 。这个模块需要定时从数据库获取最新的数据来更新自己 。在11点05分,一位程序员推送了一个数据库的“权限设置”更新。
这个权限更新本身没问题,但它和一段有漏洞的 SQL 查询代码(从数据库拿数据的指令)产生了冲突。
CF 用的是一个叫 ClickHouse 的特殊数据库 。在这个数据库上,新的权限导致那段有漏洞的代码从两个地方同时拿到了数据,结果就是拿到了一份“重复”的数据列表。
这个列表本应只有不到200项,但重复后就超出了200项。**PS:**这个200纯粹是因为CF的程序员觉得features(数据表中的数据)到不了200项
BM 模块的程序(用 Rust 语言写的)为了追求速度,提前设定好了一个“固定长度为200”(即为上文的200项)的内存空间来装这个列表 。
当程序试图把这份“超长”的重复列表塞进这个只能装200个的“盒子”时,就发生了错误 。
程序中用了一个叫 unwrap (Rust的大杀器)的指令,它的作用是:一旦遇到这种严重错误,就立刻让整个程序“崩溃”停掉。
于是,在11点28分,BM 模块一拿到错误数据就崩溃了,导致所有通过它访问网站的请求全部失败。
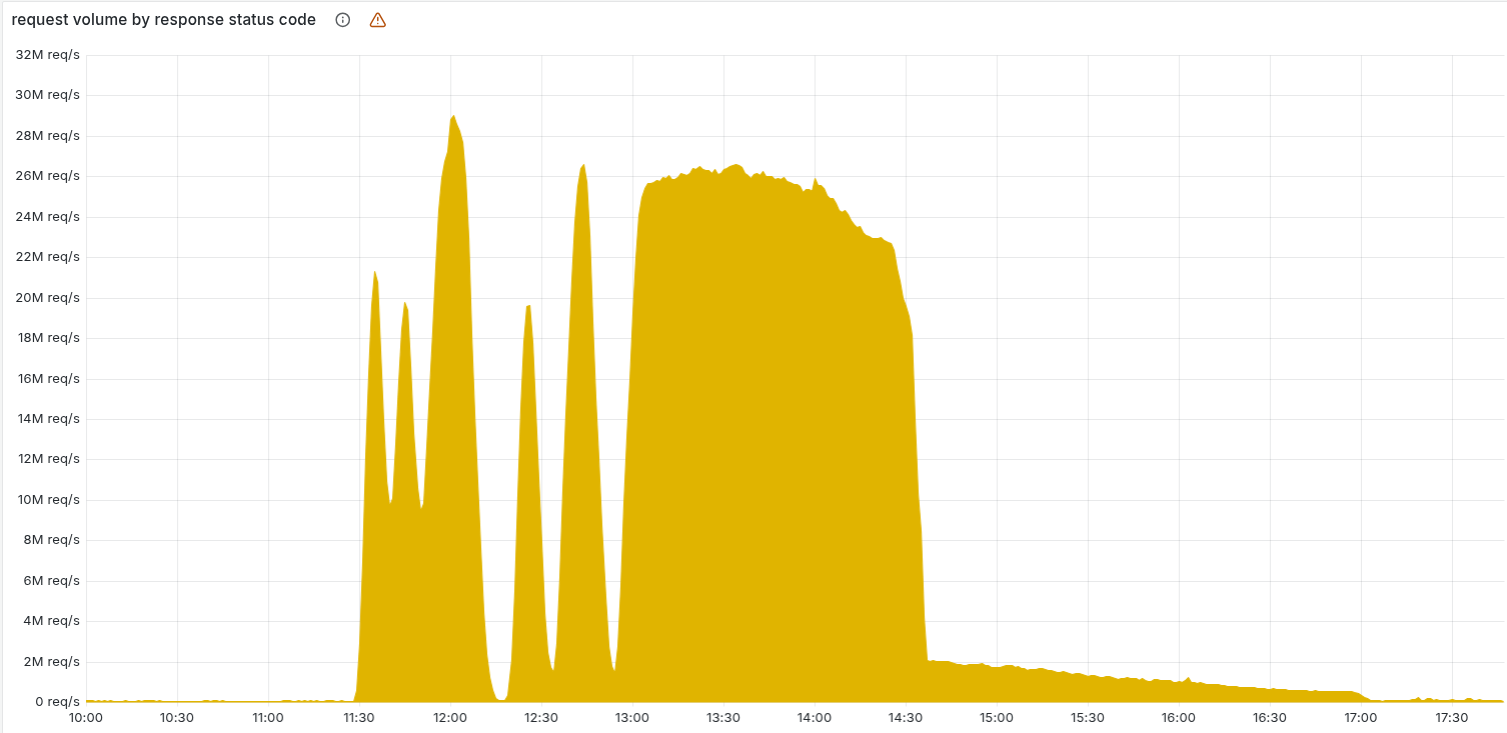
一开始,这个故障时好时坏,因为数据库更新是逐步推送的,有的机器崩溃了,有的还没 。
这种“过山车”式的报错曲线,让工程师在头两个小时里一直以为是遭到了黑客攻击(DDoS)。
直到13点30分,所有机器都更新了,故障变成了一条“平稳的直线”,工程师才意识到是内部系统出了问题。
三、解决
工程师们最终在14点24分找到了问题的根源(那段 SQL 代码和权限问题),他们先切断了 BM 模块的自动更新功能,然后手动部署了一份干净的数据,服务才开始慢慢恢复。
四、总结
这次故障的根源,其实是程序员为了“图方便”走捷径(写了有漏洞的SQL代码、使用了固定长度的数组)导致的低级错误 。视频认为,这反映出我们现在依赖的整个互联网其实非常“脆弱” ,它建立在各种追求方便的“快捷方式”之上,并且高度集中在少数几家大公司(如 CF, AWS, Google)手中。
五、起因中数据库冲突细致讲解
简单来说,这是一个“好心的权限更新”遇到了一个“有历史遗留漏洞的代码”的经典事故,而火上浇油的是它们所使用的一个特定数据库(ClickHouse)的独特工作方式。
1.历史原因
Cloudflare 的“机器人管理”(BM) 模块需要一个“特征列表”(比如IP地址、浏览器类型等)来判断是不是机器人。
这个列表信息存储在数据库 R0 中。
但由于某些历史原因,程序不能直接去 R0 拿这个列表。它必须分两步走:
- 先去一个叫 defaultdatabase 的数据库,问它:“R0 里的那个特征列表,它都包含哪些列?(即获取元数据)”
- 拿到这个“列名清单”后,再拿着清单去 R0 数据库说:“好了,按照这个清单,把数据给我。”
2.权限更新
在11点05分,工程师推送了一个更新,目的就是为了解决上面那个“笨办法”。
这个更新的作用是:“允许 BM 模块直接读取 R0 数据库的元数据(列名清单)”。
这样一来,程序以后就可以跳过第一步,直接在 R0 里完成所有操作,更简单、更高效。
3.SQL 代码
问题出在第一步(去 defaultdatabase 拿清单)的那段查询代码(SQL)上。
那段代码写得很“模糊”,它大致的意思是:“请在 system.columns 表里,把 http_request_features 这张表的所有列名都给我。”
它致命的缺陷是:它只说了要查哪张表,但没有明确说要去“哪一个数据库”里查。
4.ClickHouse 数据库的独特机制
Cloudflare 用的 ClickHouse 数据库,它的一种工作机制和我们常见的数据库(如 PostgreSQL)不一样:
普通数据库:你连接哪个数据库,就只能看到哪个数据库里的东西。
ClickHouse:它的查询权限是“隐性”的。一个查询会看到所有它有权限访问的数据库里的数据。
5.连锁反应
结果,它在 defaultdatabase 里找到了清单(第1份),又在 R0 里也找到了清单(第2份)。
最终,它把两份清单合并成一份,返回给了程序。
所以,程序(BM 模块)拿到的不再是正常的列表,而是一份所有项目都重复了一遍的“加倍列表”。